Introduction

In this paper, we are interested in modeling a how-to instructional procedure, such as a cooking recipe, with a meaningful and rich high-level representation. Specifically, we propose to represent cooking recipes and food images as cooking programs. Programs provide a structured representation of the task, capture cooking semantics and sequential relationships of actions in the form of a graph. This allows it to be easily manipulated by users and executed by agents. To this end, we build a model that is trained to learn a joint embedding between recipes and food images via self-supervision and jointly generate a program from this embedding as a sequence. To validate our idea, we crowdsource programs for cooking recipes and show that: (a) projecting the image-recipe embeddings into programs leads to better cross-modal retrieval results; (b) generating programs from images leads to better recognition results compared to predicting raw cooking instructions; and (c) we can generate food images by manipulating programs via optimizing the latent code of a GAN.
Cooking programs
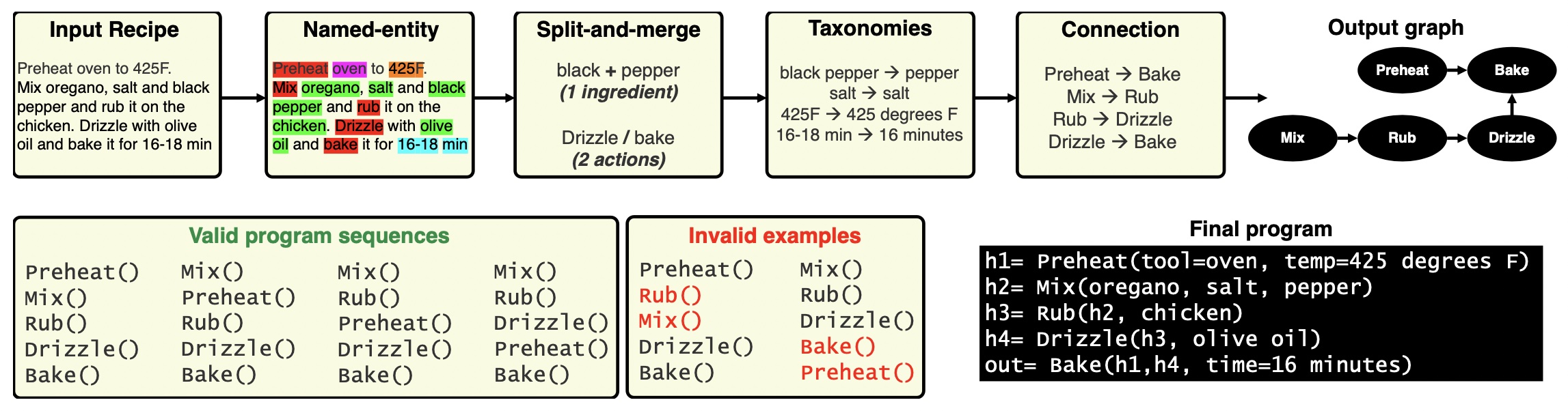
A program contains a sequence of functions that correspond to cooking actions. Each function takes as input a list of input variables (ingredients) and parameters (e.g., ingredient quantities or the way the action is performed, such as using a tool). For example, the sentence “Bake the chicken in the oven for 10 minutes at 400 degrees F” can be written as: h = Bake(chicken, tool=oven, time=10 minutes, temp=400 degrees F); The output of the function is denoted as h. For a full program, we also capture the input-output connections between the individual commands.
Crowdsourcing cooking programs is challenging as most naive annotators have no programming experience. For this reason, we split the process into four simple steps: (a) named-entity annotation, (b) split-and-merge parsing, (c) connection annotation and (d) program taxonomy. We ran experiments on Amazon Mechanical Turk (AMT) and collected programs for 3,708 recipes selected from the Recipe1M dataset.
Model: From food images and recipes to programs
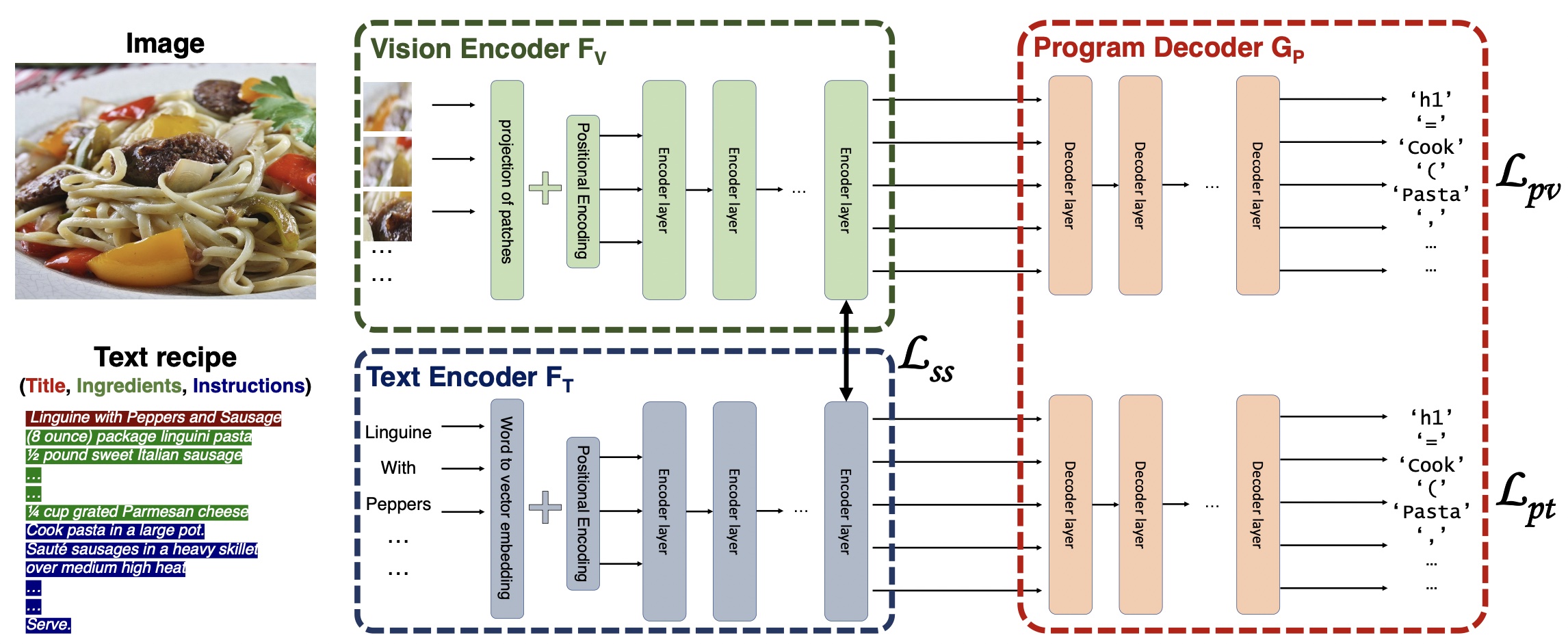
We introduce the novel task to generate cooking pro- grams from food images or cooking recipes. Given a set of images paired with their recipes and a set of programs, our goal is to learn how to generate a cooking program conditioned on an image or a recipe. Our model consists of three components: (a) a vision encoder, (b) a text encoder, and (c) a program decoder. The model is trained to embed the images and recipes into the same space via self-supervision and to generate a program from an image or a recipe embedding.
Generating food images from programs
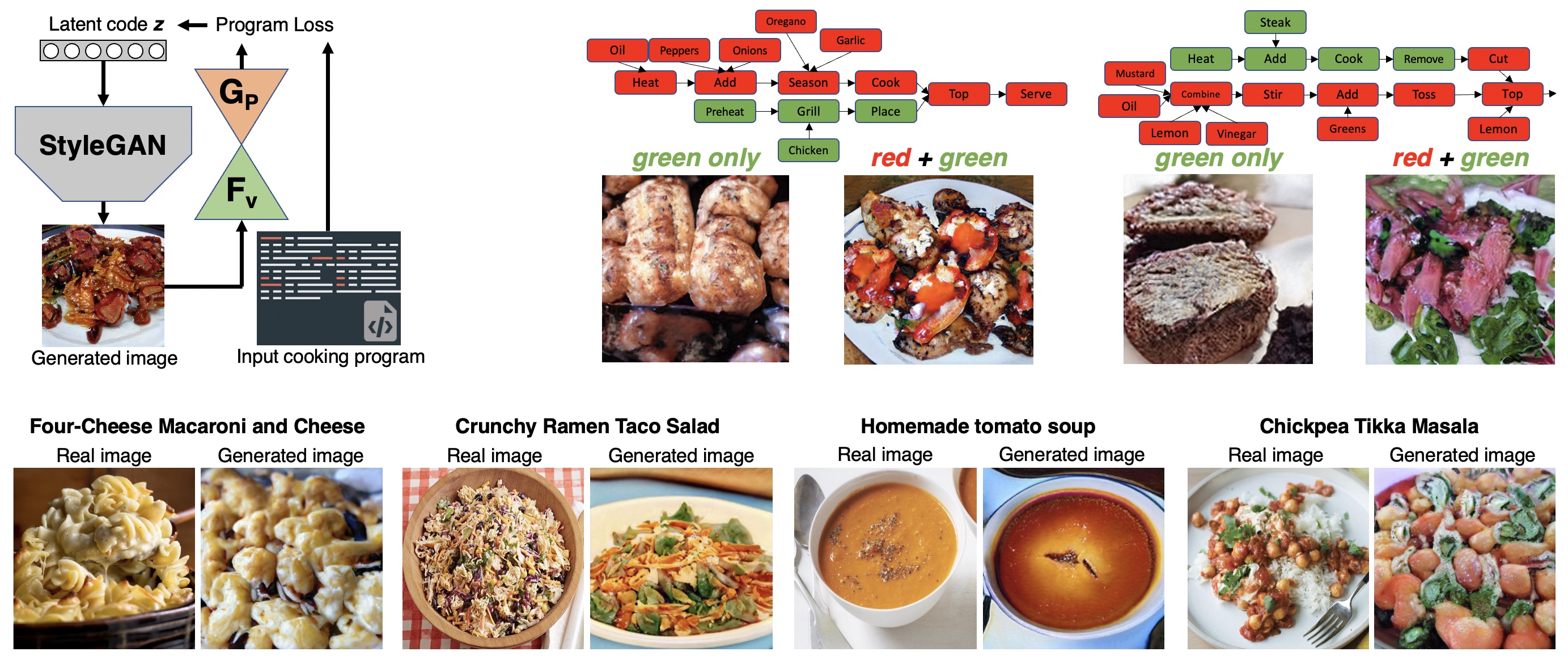
We show an interesting application of image generation conditioned on cooking programs using our model. We first train a StyleGANv2 on the images of the Recipe1M dataset. Given an initial latent vector, we use the GAN to generate an image. The image goes through the vision encoder and the program decoder to obtain a program. We compute the loss between this program and the desired input one. We use the loss to optimize z via backpropagation.
Paper

Bibtex
Acknowledgments
This work is supported by Nestle.